|
Hi! I’m Joya, a final-year Ph.D. candidate at the
Show Lab, National University of Singapore (NUS),
advised by Prof. Mike Shou.
I’m currently interning at ByteDance Seed, working with
Multimodal Interaction and World Model group, VLM base model team. View my education backgroundI obtained my bachelor's degree in School of Automotive Engineering, WUT. To chase my AI dream, I took the National Postgraduate Entrance Examination and obtained the 1st place in School of Computer Science and Technology, USTC. I obtained my master's degree from here, under the supervision of Prof. Enhong Chen, Prof. Tong Xu, and Prof. Dong Liu. I also had a research assistant at CVML@NUS group, working closely with Prof. Angela Yao. |

|
|
|

|
Invited talk at ByteDance Seed Video Gen Team on Learning Omni Video Stream. Slides will be available soon. |


|
Invited talk at Alibaba Qwen Team on VideoLLM-online: Online LLM for Streaming Video. |
 |
Core organizer of LOVEU: LOng-form VidEo Understanding Towards Multimodal AI Assistant and Copilot Workshop @ CVPR'24.
We have uploaded the recorded video: Excellent talks given by Prof. Dima Damen, Prof. Marc Pollefeys, Dr. Chunyuan Li. Great winner talks on Track1: Long-Term Video Question Answering and Track 2A: Text-Guided Video Editing & Track 2B: Text-to-Video Generation. |
|
|
 |
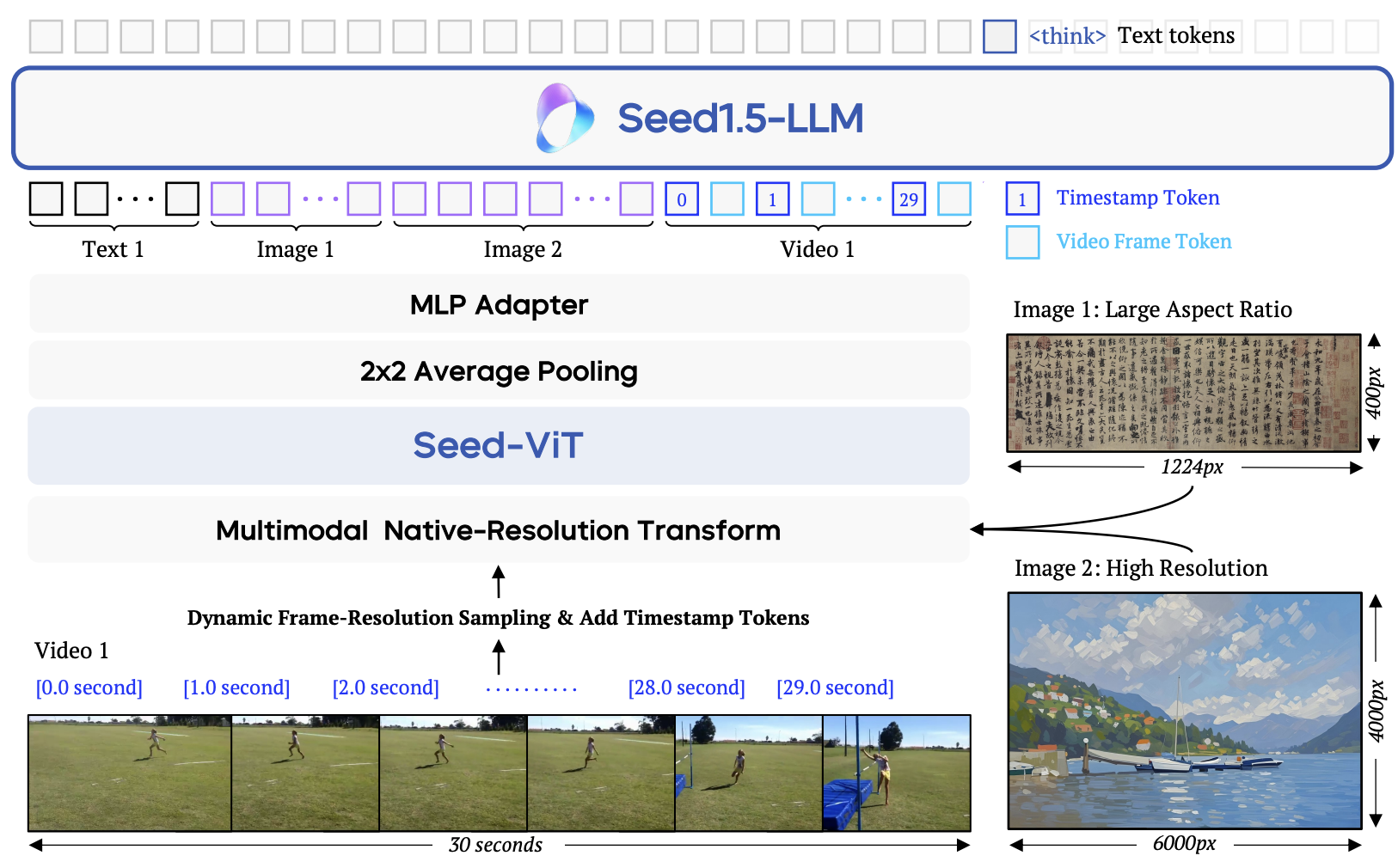
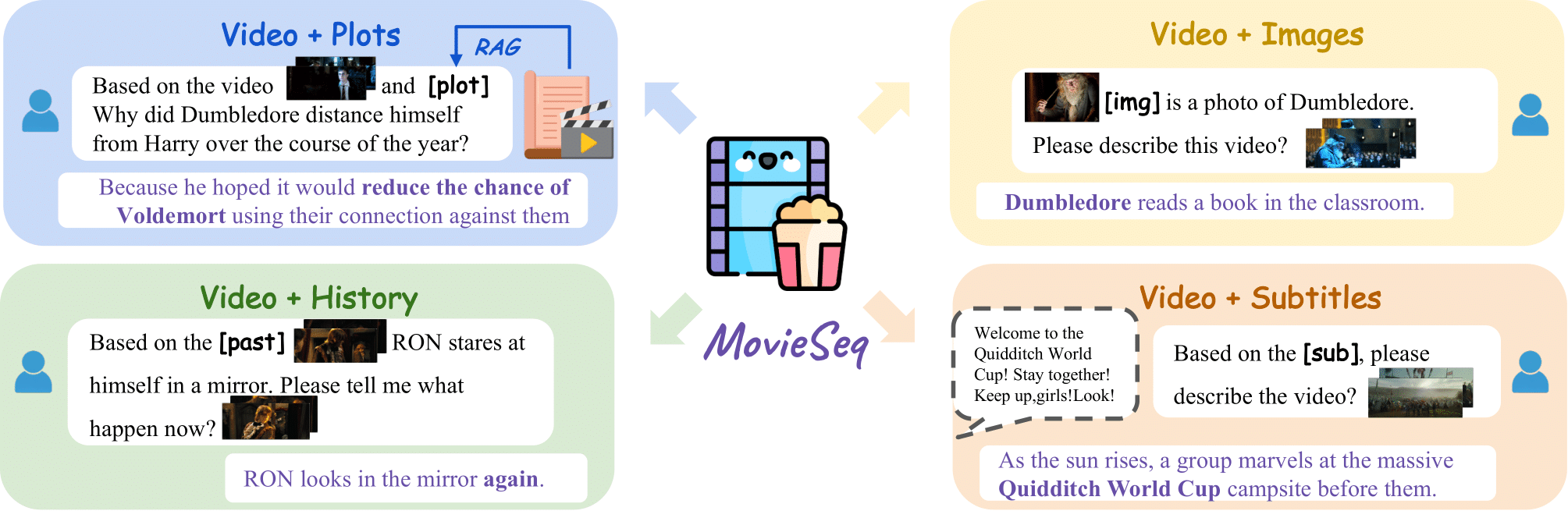
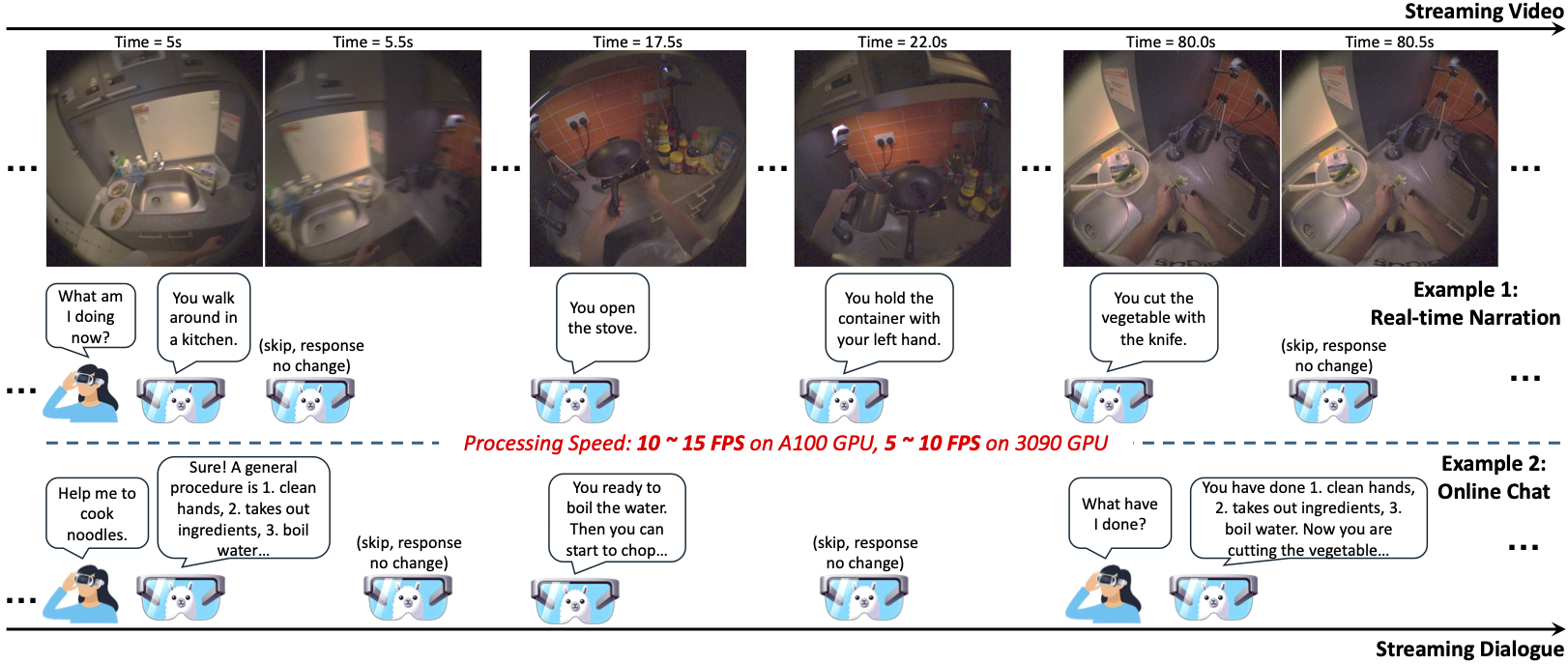
ByteDance Seed. I contributed to the streaming capability. arXiv, 2025 Homepage |
 |
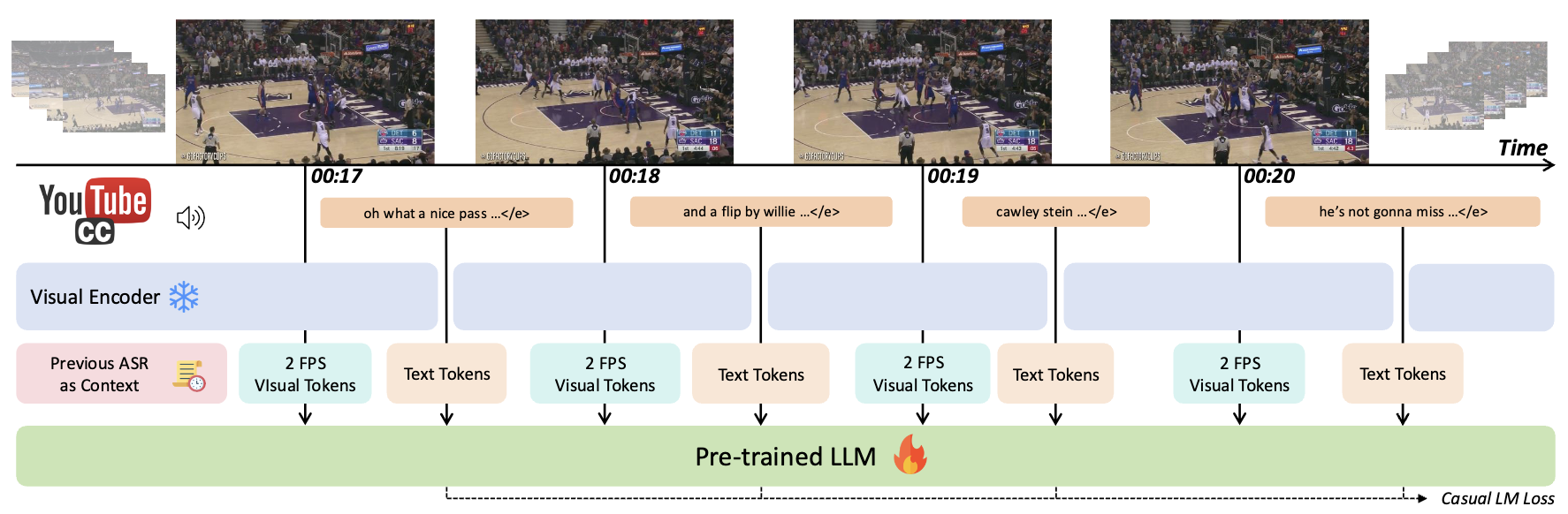
ByteDance Seed. I contributed to the streaming capability and the interactive demo. arXiv, 2025 Homepage / HuggingFace Demo / Github / API |
 |
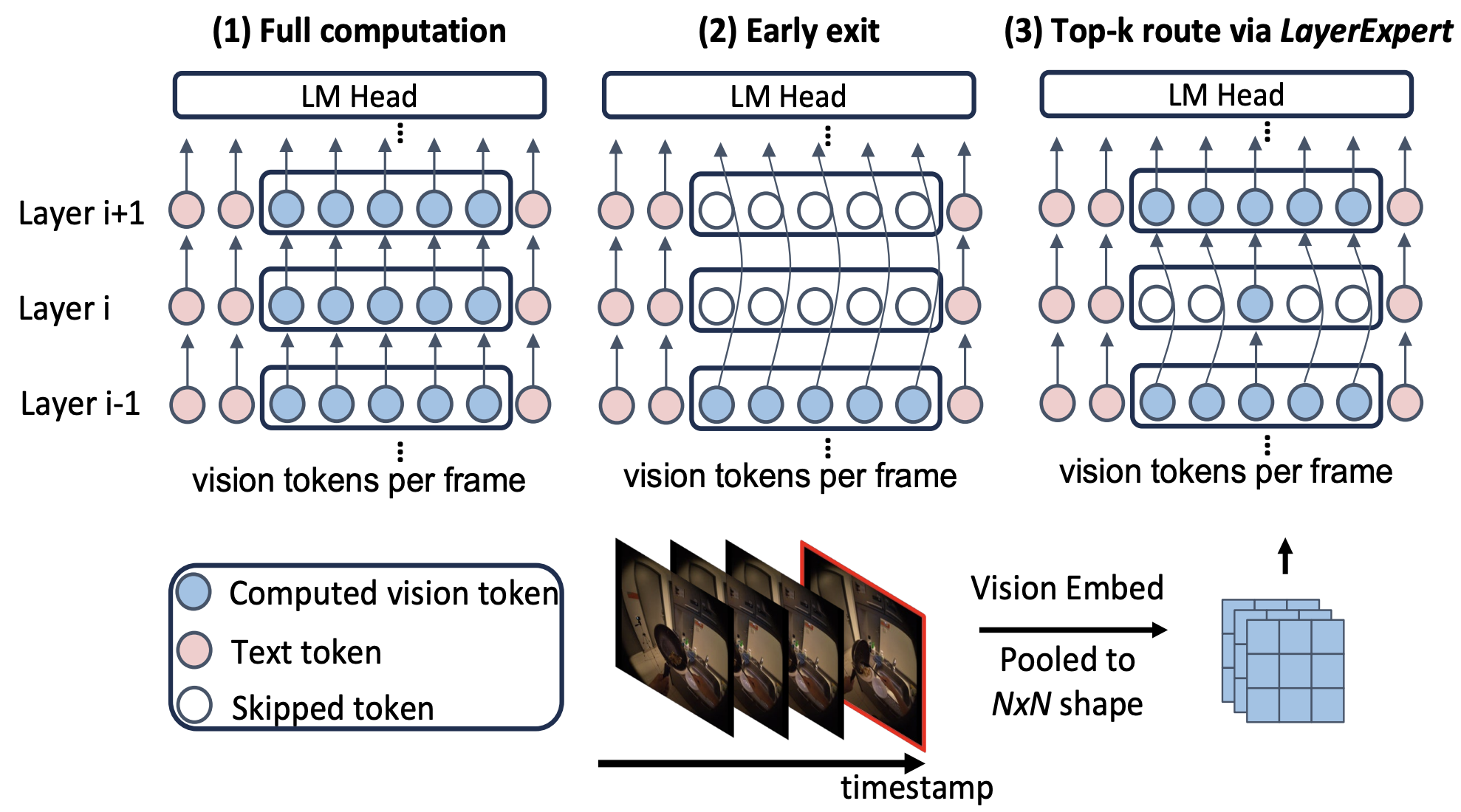
Joya Chen*, Ziyun Zeng*, Yiqi Lin*, Wei Li, Zejun Ma, Mike Zheng Shou CVPR, 2025 All open-sourced! Checkpoints, Pre-training & SFT Datasets, Training Code, Evaluation Benchmark, Gradio Demo |
 |
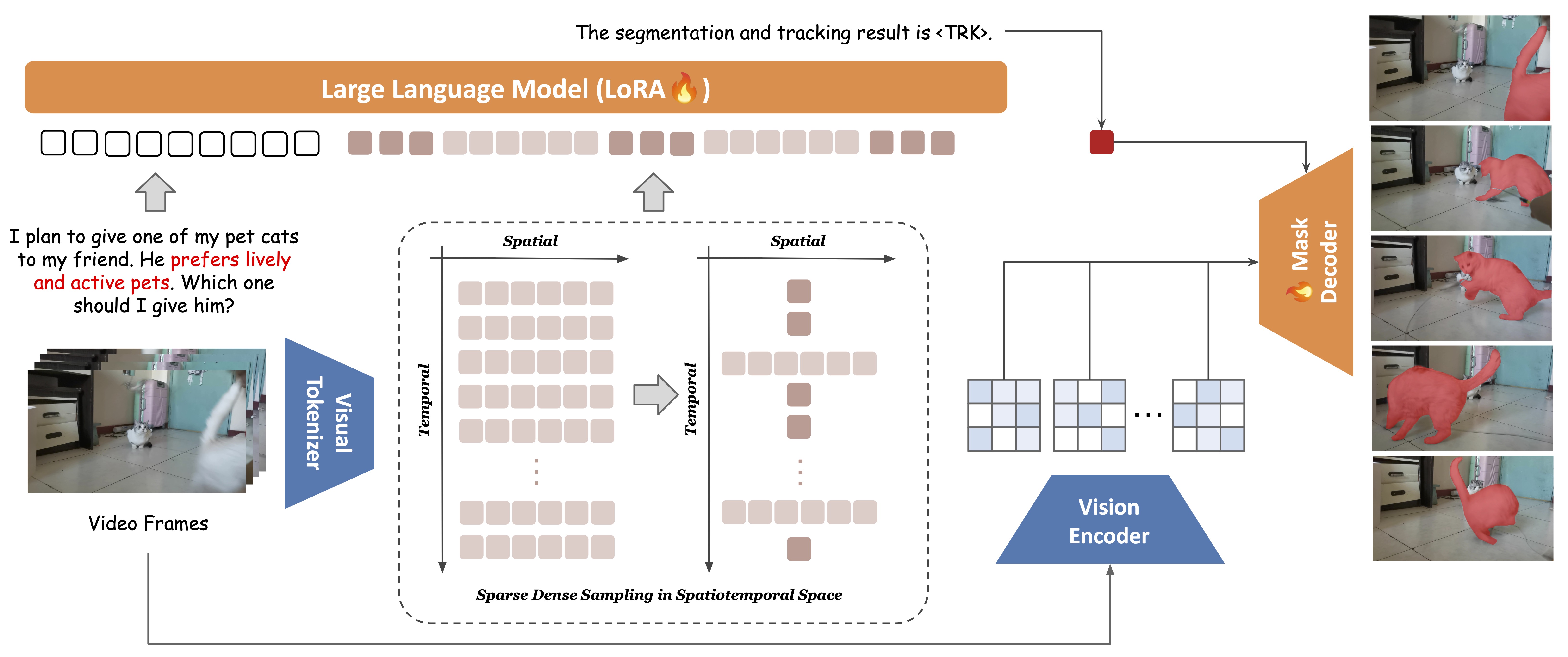
Shiwei Wu*, Joya Chen*, Kevin Qinghong Lin, Qimeng Wang, Yan Gao, Qianli Xu, Tong Xu, Yao Hu, Enhong Chen, Mike Zheng Shou NeurIPS, 2024 |
 |
Zechen Bai, Tong He, Haiyang Mei, Pichao Wang, Ziteng Gao, Joya Chen, Lei Liu, Zheng Zhang, Mike Zheng Shou NeurIPS, 2024 Code |
 |
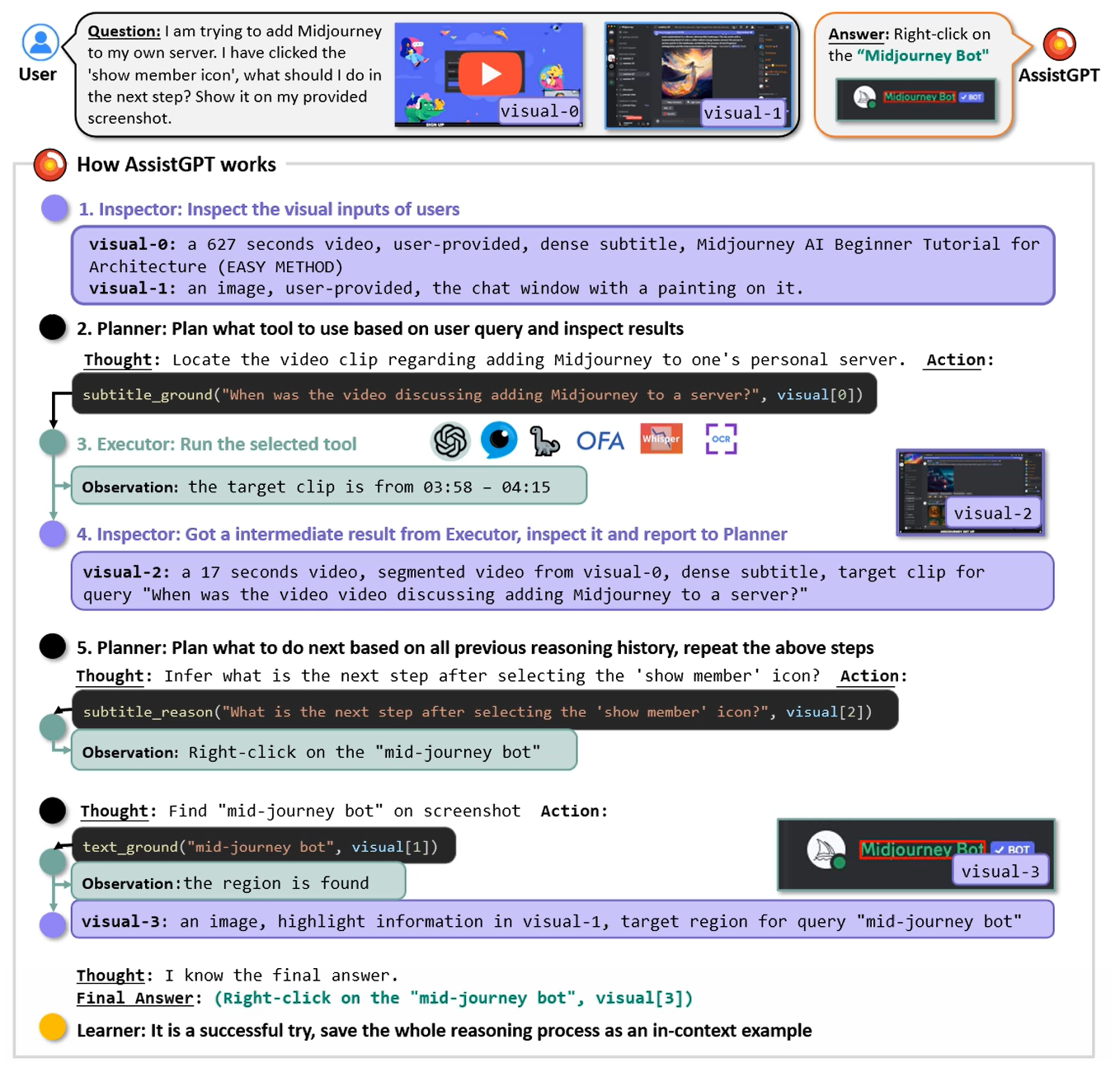
Kevin Qinghong Lin, Pengchuan Zhang, Difei Gao, Xide Xia, Joya Chen, Ziteng Gao, Jinheng Xie, Xuhong Xiao, Mike Zheng Shou ECCV, 2024 Code |
 |
Joya Chen, Zhaoyang Lv, Shiwei Wu, Kevin Qinghong Lin, Chenan Song, Difei Gao, Jia-Wei Liu, Ziteng Gao, Dongxing Mao, Mike Zheng Shou CVPR, 2024 Homepage: Paper, Code, Data, Demo, Checkpoints |
 |
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, Eugene Byrne, Zach Chavis, Joya Chen, ..., Mike Zheng Shou, Michael Wray CVPR (Oral), 2024 https://ego-exo4d-data.org/ |
 |
Difei Gao, Lei Ji, Luowei Zhou, Kevin Qinghong Lin, Joya Chen, Zihan Fan, Mike Zheng Shou arXiv, 2023 Paper / Page |
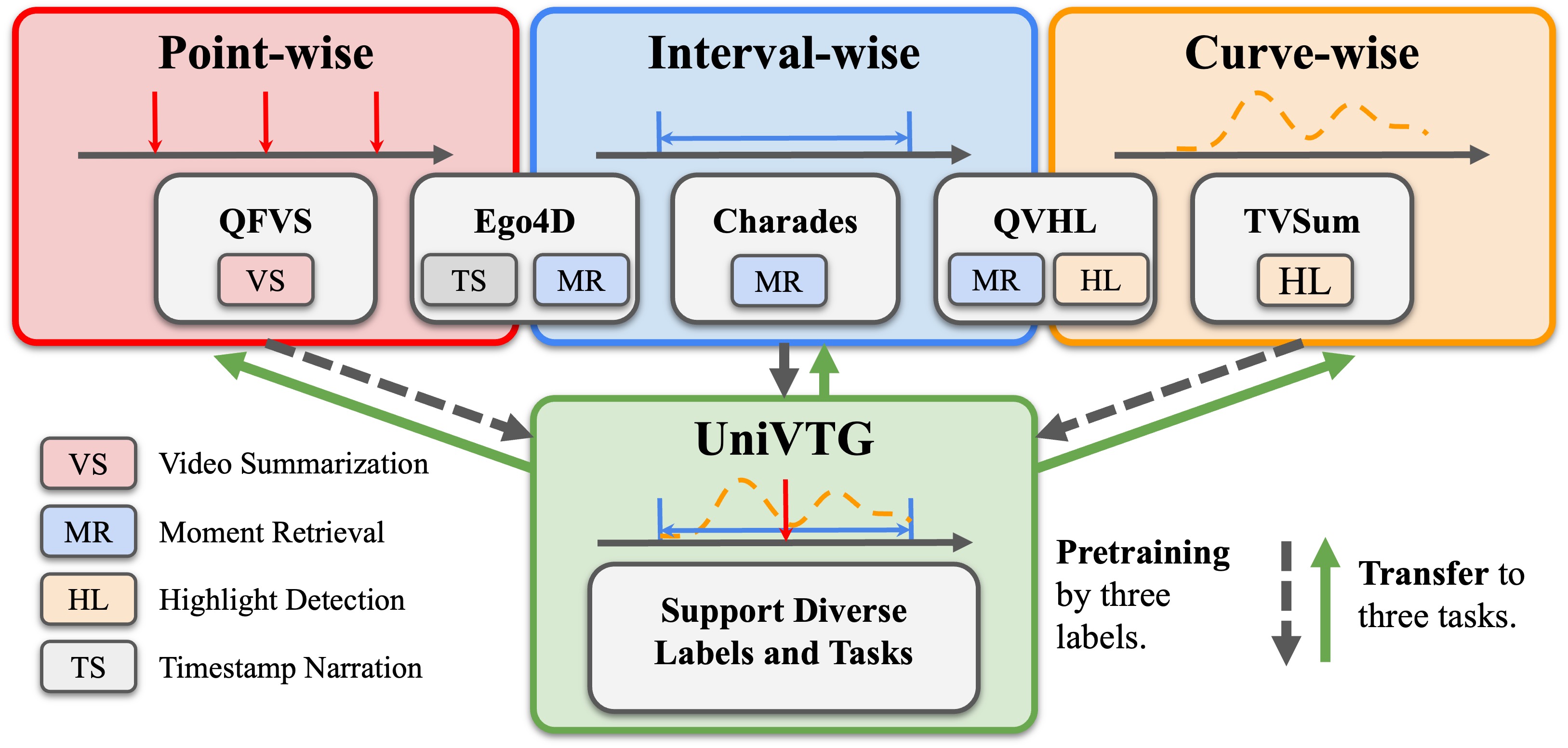 |
Kevin Qinghong Lin, Pengchuan Zhang, Joya Chen, Shraman Pramanick, Difei Gao, Alex Jinpeng Wang, Rui Yan, Mike Zheng Shou ICCV, 2023 Paper / Code / Demo |
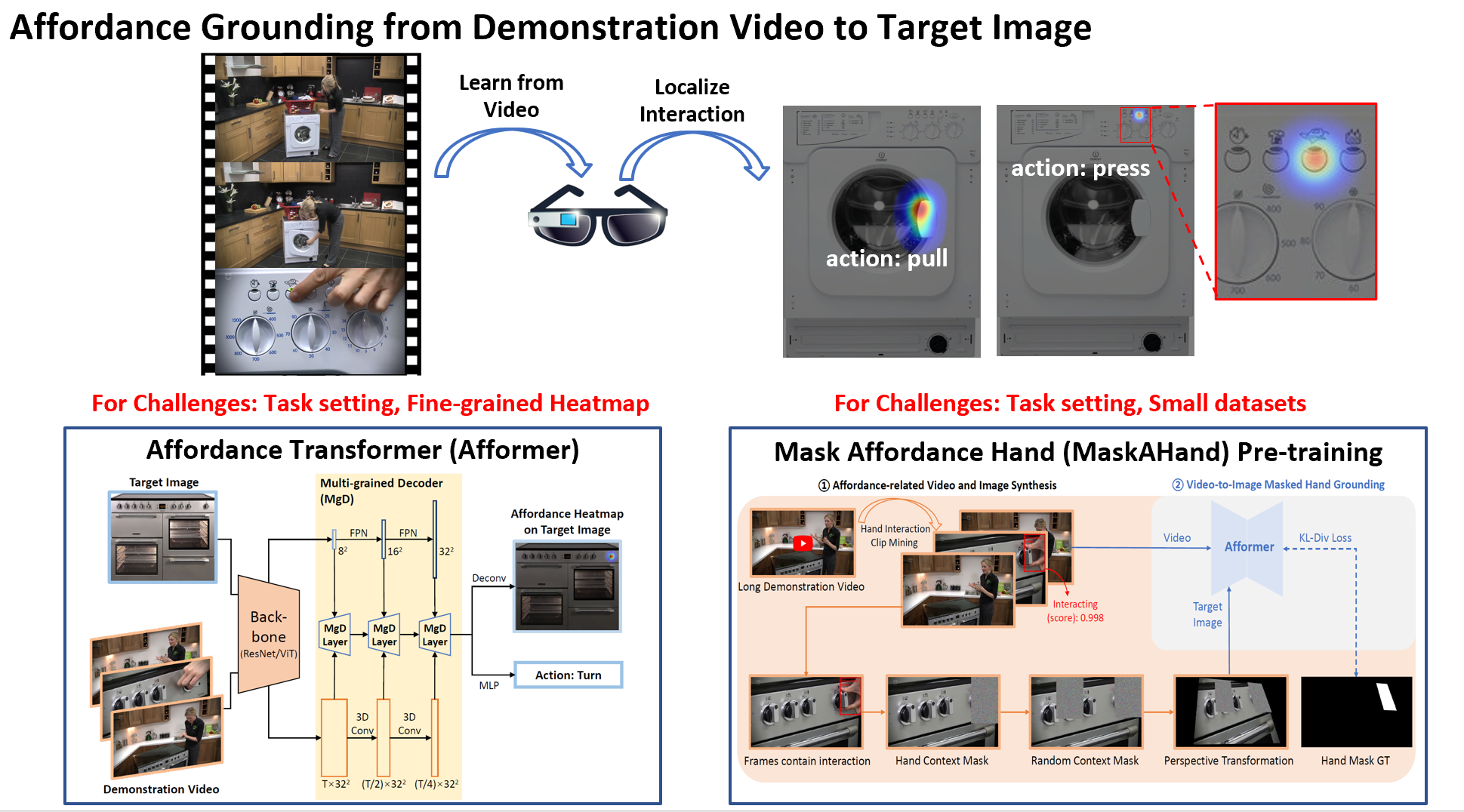 |
Joya Chen, Difei Gao, Kevin Qinghong Lin, Mike Zheng Shou CVPR, 2023 Paper / Code |
 |
Joya Chen*, Kai Xu*, Yuhui Wang, Yifei Cheng, Angela Yao ICLR, 2023 OpenReview / arXiv / Code |
 |
Benita Wong*, Joya Chen*, You Wu*, Stan Weixian Lei, Dongxing Mao, Difei Gao, Mike Zheng Shou ECCV, 2022 Paper / Page / Code / Challenge@CVPR'22 |
 |
Joya Chen, Dong Liu, Tong Xu, Shiwei Wu, Yifei Chen, Enhong Chen IEEE Transactions on Image Processing, 2021 Paper / Code |
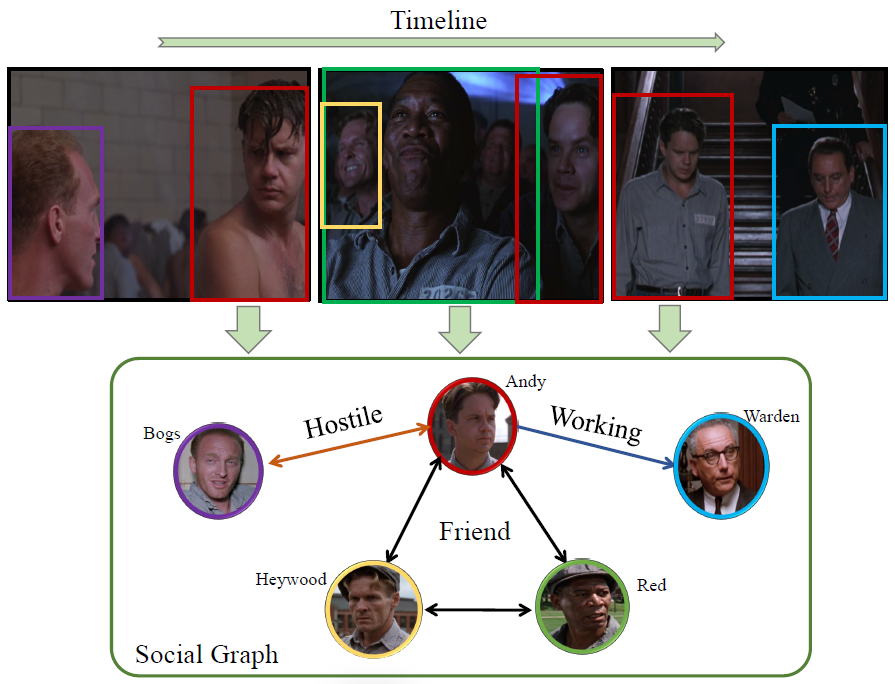 |
Shiwei Wu, Joya Chen, Tong Xu, Liyi Chen, Lingfei Wu, Yao Hu, Enhong Chen ACM MM (Oral), 2021 Paper |
|
|
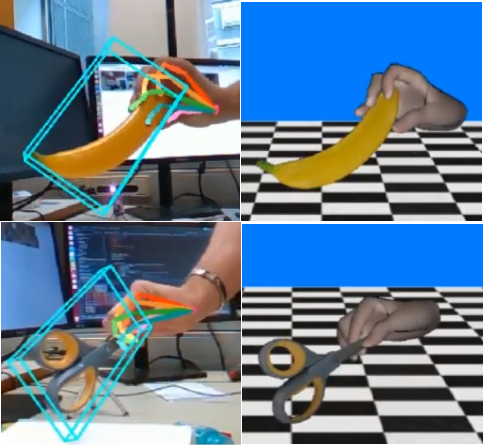 |
Ranked 1st in HO-3D Leaderboard in Mesh Error/AUC and F@15mm metrics in Dec. 2020 |
 |
Ranked 1st in PASCAL VOC Object Detection Competition 3 Leaderboard in Sep. 2018 |
|
|
|
Thanks go to Jon Barron's website! |